
哈希算法
哈希函数(散列函数)定义
公式表示形式:
h = H ( m ) h=H(m)
h=H(m)
函数说明:
m mm:任意长度消息(不同算法实现,长度限制不同,有的哈希函数(SHA-3)不限制消息长度,有的限制(SHA-2),但即使有限制其长度也非常大,可以认为是任意长度消息)
H HH:哈希函数
h hh:固定长度的哈希值
典型的散列函数都有非常大的定义域,比如SHA-2最高接受(2 64 − 1 ) / 8 2^{64}-1)/82
64
−1)/8长度的字节字符串。同時散列函數一定有着有限的值域,比如固定长度的比特串(例如:256,512)。在某些情况下,散列函数可以设计成具有相同大小的定义域和值域间的單射。
相关概念
哈希函数定义——密码哈希函数是一类数学函数,可以在有限合理的时间内,将任意长度的消息压缩为固定长度的二进制串,其输出值称为哈希值,也称散列值。
碰撞定义——是指两个不同的消息在同一哈希函数作用下,具有相同的哈希值。
哈希函数的安全性——是指在现有的计算资源(包括时间、空间、资金等)下,找到一个碰撞是不可行的。
抗弱碰撞性——对于给定的消息M 1 M_1M
1
,要发现另一个消息M 2 M_2M
2
,满足H ( M 1 ) = H ( M 2 ) H(M_1)=H(M_2)H(M
1
)=H(M
2
)在计算上是不可行的。
抗强碰撞性——找任意一对不同的消息M 1 M_1M
1
,M 2 M_2M
2
,使H ( M 1 ) = H ( M 2 ) H(M_1)=H(M_2)H(M
1
)=H(M
2
)在计算上是不可行的。
雪崩效应——当一个输入位发生变化时,输出中的每一位均有50%的概率发生变化。
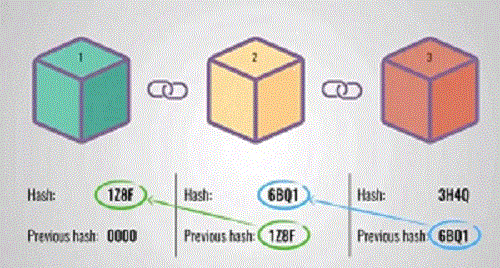
下图形象的说明了哈希函数:
哈希算法就是以哈希函数为基础构造的,常用于实现数据完整性和实体认证。一个优秀的 hash 算法,将能实现:
正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。
哈希函数的性质
抗碰撞性
哈希函数的抗碰撞性是指寻找两个能够产生碰撞的消息在计算上是不可行的。但找到两个碰撞的消息在计算上不可行,并不意味着不存在两个碰撞的消息。哈希函数是把大空间上的消息压缩到小空间上,碰撞肯定存在。只是计算上是不可行的。例如,如果哈希值的长度固定为256位,显然如果顺序取1 , 2 , ⋯ , 2 256 + 1 1,2,\cdots,2^{256}+11,2,⋯,2
256
+1这2 256 + 1 2^{256}+12
256
+1个输入值,计算它们的哈希值,肯定能够找到两个输入值,使得它们的哈希值相同。
原像不可逆
原像不可逆,指的是知道输入值,很容易通过哈希函数计算出哈希值;但知道哈希值,没有办法计算出原来的输入值。
难题友好性
难题友好性指的是没有便捷的方法去产生一满足特殊要求的哈希值。
一个哈希函数H HH称为难题友好的,如果对于每个n nn位的输出y yy,若k kk是从一个具有较高不可预测性(高小熵)分布中选取的,不可能以小于2 n 2^n2
n
的时间找到一个x xx,使H ( k ∣ ∣ x ) = y H(k||x)=yH(k∣∣x)=y。
为了引申出工作量证明POW的原理,考虑一个由哈希函数构成的解谜问题:已知哈希函数H HH,一个高小熵分布的值v a l u e valuevalue以及目标范围Y YY,寻找x xx,使得H ( v a l u e ∣ ∣ x ) ∈ Y H(value||x) \in YH(value∣∣x)∈Y。
这个问题等价于需要找到一个输入值,使得输出值落在目标范围Y YY内,而Y YY往往是所有的输出值的一个子集。实际上,如果一个哈希函数H HH的输出位n nn位,那么输出值可以是任何一个0 00~2 n 2^n2
n
范围内的值。预定义的目标范围Y YY的大小决定了这个问题的求解难度。如果Y YY包含所有n nn比特的串,那么问题就简单了,但如果Y YY只包含一个元素,那么这个求解是最难的,相当于给定一个哈希值,找出其中一个原像,原像不可逆的性质说明了这个难度。事实上,由于v a l u e valuevalue具有高小熵分布,这确保了除了随机尝试x xx值以完成搜寻那个很大的空间外,没有其他有效的途径了。
哈希函数的难题友好性构成了基于工作量证明的共识算法的基础。通过哈希运算得出的符合特定要求的哈希值,可以作为共识算法中的工作量证明。这里比特币的安全保证依赖于哈希函数的安全性,如果哈希函数被攻破,可以想象POW共识算法就失效了,不用算力达到51 % 51\%51%就可以攻击了。
小熵(min-entropy)是信息理论中衡量某个结果的可预测性的一个指标。高小熵值的是变量呈均匀分布(随机分布)。如果我们从对分布的值进行随机抽样,不会经常抽到一个固定的值。例如,如果在一个128位的数中随机选一个固定的数n nn,那么选到该数的几率是1 / 2 128 1/2^{128}1/2
128
。
典型哈希函数
SHA256
SHA256属于SHA(Secure Hash Algorithm,安全哈希算法)家族一员,是SHA-2算法簇中的一类,对于小于2 64 2^{64}2
64
位的消息,产生一个256位的消息摘要。
SHA-256其计算过程分为两个阶段:消息的预处理和主循环。在消息的预处理阶段,主要完成消息的填充和扩展填充,将所有输入的原始消息转换为n nn个512比特的消息块,之后对每个消息块利用SHA256压缩函数进行处理。下面讲述的是如何计算Hash值,目前还没有完全理解,列在这里是为了有个宏观的概念,大致知道是什么回事,以后需要的时候再深入学习理解。
SHA256计算步骤:
step1: 附加填充比特。对报文进行填充使报文长度 n ≡ ( 448 m o d 512 ) n \equiv (448 \ mod \ 512)n≡(448 mod 512),填充比特数范围是1到512,填充比特串的最高位为1,其余位为0。(448=512-64,为了下面的64位)
step2 : 附加长度值。将用64-bit表示初始报文(填充前)的位长度附加在step1的结果后(低字节位优先)。
step3: 初始化缓存。使用一个256bit的缓存来存放该哈希函数的中间值及最终结果。
缓存表示为:A=0x6A09E667 , B=0xBB67AE85 , C=0x3C6EF372 , D=0xA54FF53A,
E=0x510E527F , F=0x9B05688C , G=0x1F83D9AB , H=0x5BE0CD19
step4: 处理512bit(16个字)报文分组序列。该算法使用了六种基本逻辑函数,由64步迭代运算组成。每步都以256-bit缓存值ABCDEFGH为输入,然后更新缓存内容。每步使用一个32-bit 常数值Kt 和一个32-bit Wt。Kt是常数值,在伪代码中有它的常数值定义。Wt是分组之后的报文,512 bit=32bit*16,也就是Wt t=1,2…16由该组报文产生。Wt t=17,18,…,64由前面的Wt按递推公式计算出来。Wt递推公式在下面的伪代码有。
step5 :所有的512-bit分组处理完毕后,对于SHA-256算法最后一个分组产生的输出便是256-bit的报文摘要。
SHA256计算流程
这里面公式太多,就直接截图了。
伪代码实现
可参考https://en.wikipedia.org/wiki/SHA-2。
RIPEMD160
RIPEMD (RACE Integrity Primitives Evaluation Message Digest,RACE原始完整性校验讯息摘要)是一种加密哈希函数。RIPEMD-160是以原始版RIPEMD所改进的160位元版本,而且是RIPEMD系列中最常见的版本。